In Chapter 5 we posed the t-a-p model variation with individual \(t_u\) parameters for each combination of raters and Class 1 ratings \((R_u,k_u)\), with log-likelihood as
where \(n_u\) is the number of times the ratings combination \((R_u,k_u)\) was observed, and \(t_u\) is the expected average of true Class 1 cases within that group. The model is fit to the data by maximizing the likelihood function with the Stan script below.
Show the code
//// Model specification for estimating t_u for each (N_r,N_c) type, with// average a and p parameters. //// Learn more about model development with Stan at://// http://mc-stan.org/users/interfaces/rstan.html// https://github.com/stan-dev/rstan/wiki/RStan-Getting-Started//// functions to make the code simpler belowfunctions {real p_true(real a, real s) { // binomial probability forreturn a + (1.0-a)*s; // subjects that are class 1 in reality }real p_false(real a, real s) { // binomial probability forreturn (1.0-a)*s; // subjects that are class 0 in reality }}// The data provided from the ratingsdata {int<lower=0> N; // number of rows of dataarray[N] int<lower=0> N_r; // number of raters for a count pairarray[N] int N_c; // count of ratings of category 1 for count pairarray[N] int<lower=0> n; // multiplicity of this (N_r, N_c) pair}// Parameters to estimateparameters {real<lower=0, upper = 1> a; // average accuracy real<lower=0, upper = 1> p; // rate of class 1 ratings when inaccuratearray[N] real<lower=0, upper = 1> t; // estimated true class 1 rate for each // (N_r, N_c) pair}// We model the count of 1s (Class 1 ratings) by the binomial mixture described// in Chapter 5 at kappazoo.com. // cf http://modernstatisticalworkflow.blogspot.com/2016/10/finite-mixture-models-in-stan.htmlmodel { a ~ uniform(0,1); // flat priors for all parameters, since we are on [0,1] t ~ uniform(0,1); p ~ uniform(0,1);for(i in1:N) { // for each subject ratedtarget += n[i] * // multiplicity of the (N_r, N_c) pair log_sum_exp( log(t[i]) + binomial_lpmf(N_c[i] | N_r[i], p_true(a,p)), log(1-t[i]) + binomial_lpmf(N_c[i] | N_r[i], p_false(a,p))); }}
We can test this idea with simulated rates that have 200 subjects, 30 raters each, with parameters \(t = .6\), \(a = .3\), and \(p = .6\). We will fit the model to the data and compare the estimated \(t_u\) values to the values derived from the average t-a-p model and the rating counts, with
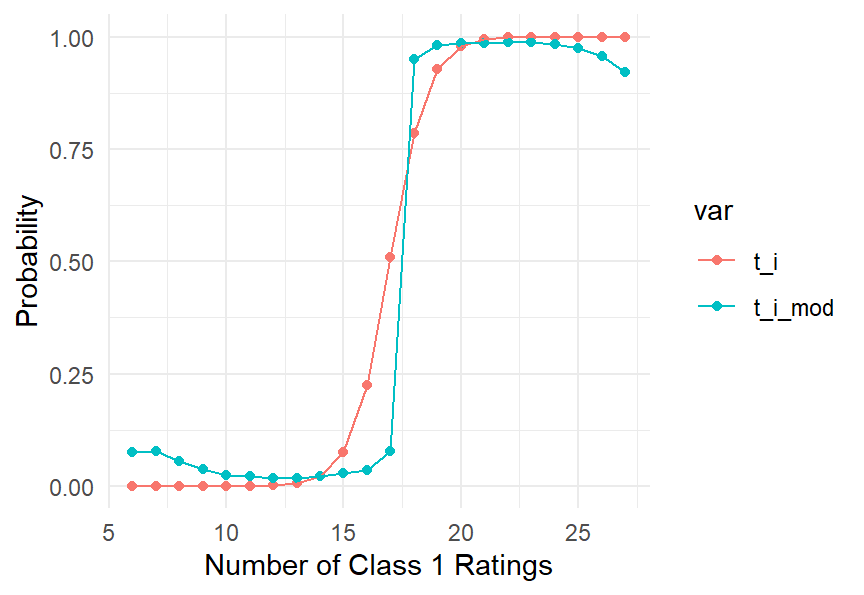
Figure 1: Conditional probability of a subject being true Class 1 given a number of Class 1 ratings from 30 raters. The comparison shows model-derived values (red) and computed values with t_u parameters (blue).
The red curve in Figure 1 is the expected values for \(t_i\) that are derived from Equation 2, which traces a smooth sigmoid. If the count of Class 1 ratings is \(k<14\), the subject is almost certainly Class 0 in reality. If the count is \(k>20\), the subject is almost certainly Class 1. Between those values, there’s a smooth transition. For example, with 17 Class 1 ratings, half of the subjects are expected to be in each class.
The blue curve shows the estimated \(t_i\) values from the inferential computation based on Equation 1, as implemented in the Stan code. In the middle of the plot, the transition is more like a step function than a sigmoid. This is a consequence of the likelihood maximization, which favors values of \(t_u\) that are close to zero or one. To see that, consider one of the unique ratings combinations \((R_u,k_u)\). The likelihood function is
Unless the binomial probabilities are each .5, one of them will be larger than the other. Suppose that the calculation is \(.6 t_u + .4 \bar{t_u}\). Since \(t_u + \bar{t_u}= 1\), the likelihood is maximized when \(t_u = 1\) and \(\bar{t_u} = 0\). More generally, likelihood will be optimized by setting \(t_u\) to 1 when the binomial probability on the left (the case when the true class is 1) is greater than .5, and to 0 when it is less than .5. This is why the blue curve is more like a step function than a sigmoid. When the binomial probabilities in Equation 3 are equal to .5, the posterior distribution for \(t_u\) is bimodal, with modes near zero and one.
The left and right tails of the blue curve in Figure 1 are biased away from their true values (e.g. on the right it curves down, away from 1). This is due to a limitation in estimating parameters with the Stan model that defines the parameters on \([0,1]\). The parameter values are taken from the modes of the posterior distributions to mitigate this problem (using averages is much worse), but it’s still evident here. One approach to this problem is to use a variable transformation, as will be taken up in the Chapter 5 discussion of Bayesian methods (not currently complete).
The main conclusion from this exercise is that we are better off using the model’s expected values for \(t_u\), which are used to assign each subject a \(t_i\) value, rather than allowing \(t_u\) to be free parameters in the model. This implies a two-step process for hierarchical models, where we first estimate the average t-a-p parameters, use those to estimate the \(t_u\) values, and then consider other parameters as desired. That approach can be thought of as a single step in an Expectation-Maximization algorithm.